Sequential Neural Likelihood Estimation with C++
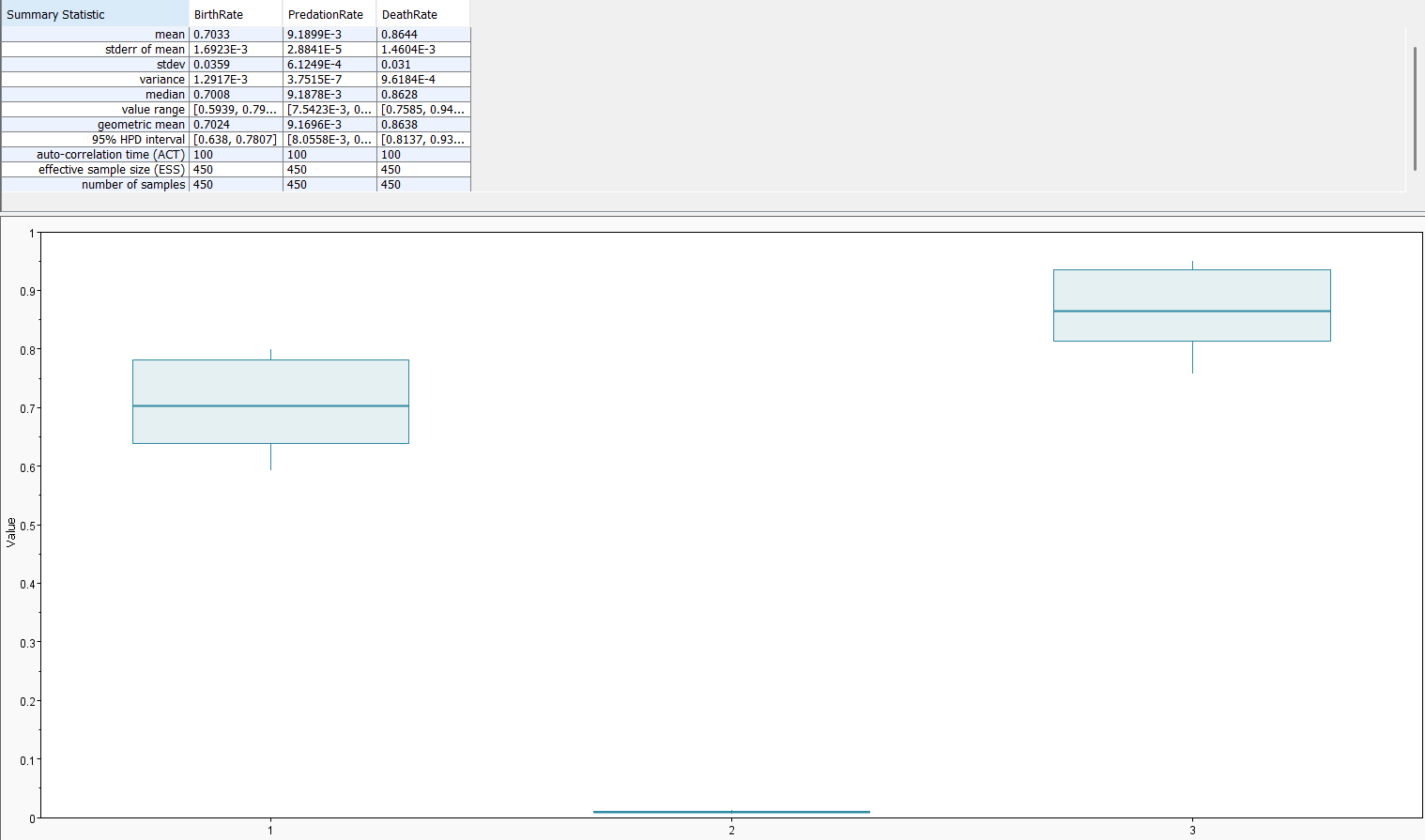
A recent pre-print by Blassel et al. (2025) renewed my interest in simulation-based inference. In this post, I revisit my sequential neural likelihood estimator for the partially observed stochastic Lotka–Volterra model, reimplemented in C++ using LibTorch and Boost. I assume familiarity with that earlier post and with SNLE in general, and concentrate here on providing C++ implementation. The model itself is nearly identical, with the exception that predator birth is now directly tied to predation in the Gillespie simulator. I also decided that this time I would run Markov chain Monte Carlo with my neural likelihood and determine how good my posterior distributions for the parameters \(\beta_{birth}\), \(\beta_{predation}\), \(\beta_{death}\). In this case, we had \((\beta_{birth},\beta_{predation}, \beta_{death}) = (0.75,0.01,0.9)\). The posterior mass concentrates around the true parameters, indicating that our neural likelihood captures the relevant structure of the simulator for these parameter choices.
CMakeLists.txt
cmake_minimum_required(VERSION 3.20)
project(SNLE-LV LANGUAGES CXX)
set(CMAKE_CXX_STANDARD 23)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_EXTENSIONS OFF)
set(CMAKE_PREFIX_PATH "/libtorch/")
find_package(Torch REQUIRED)
find_package(Boost REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_executable(snle_lv snle_lv.cpp)
target_link_libraries(snle_lv "${TORCH_LIBRARIES}")
target_link_libraries(snle_lv Boost::boost)
snle_lv.cpp
#include <iostream>
#include <fstream>
#include <torch/torch.h>
#include <boost/random/mersenne_twister.hpp>
#include <boost/random/exponential_distribution.hpp>
#include <boost/random/uniform_01.hpp>
#include <boost/random/exponential_distribution.hpp>
/**
* @brief This is the conditional autoregressive normalizing flow we will use to estimate the
* likelihood. The general layout here is that there are some embedding layer that takes in the conditionals
* of the probability distribution
*/
struct ConditionalAutoregressiveFlow : torch::nn::Module {
ConditionalAutoregressiveFlow(void) = delete;
ConditionalAutoregressiveFlow(int nF = 3) : numFlows(nF),
l1e(register_module("l1e", torch::nn::Linear(5, 16))) {
register_module("flow1Lin", flow1Lin);
register_module("flow2Lin", flow2Lin);
register_module("flow1Param", flow1Param);
register_module("flow2Param", flow2Param);
for(int i = 0; i < numFlows; i++){
flow1Lin->push_back(torch::nn::Linear(16, 16));
flow2Lin->push_back(torch::nn::Linear(17, 16));
flow1Param->push_back(torch::nn::Linear(16, 2));
flow2Param->push_back(torch::nn::Linear(16, 2));
}
}
/**
* @brief Sends data in the normalizing direction and returns the NLL from the Base distribution
*/
torch::Tensor forward(torch::Tensor augmentedData){
auto e = torch::log(augmentedData.index({torch::indexing::Slice(), torch::indexing::Slice(0, 5)}).clone());
auto data = torch::log(augmentedData.index({torch::indexing::Slice(), torch::indexing::Slice(5, 7)}).clone());
int conditionalDim = 1;
torch::Tensor jacobianSum = torch::sum(data, -1);
e = torch::relu(l1e(e));
for(int i = 0; i < numFlows; i++){
// Handle Non-Conditional Affine
auto localEmbed = torch::relu(flow1Lin[i]->as<torch::nn::Linear>()->forward(e));
auto p1 = flow1Param[i]->as<torch::nn::Linear>()->forward(localEmbed);
auto scale1 = torch::softplus(p1.index({torch::indexing::Slice(), 1}));
auto shift1 = p1.index({torch::indexing::Slice(), 0});
auto nonCondView = data.index({torch::indexing::Slice(), conditionalDim ^ 1});
nonCondView.div_(scale1);
nonCondView.sub_(shift1);
jacobianSum -= torch::log(scale1);
// Handle Conditional Affine
localEmbed = torch::relu(
flow2Lin[i]->as<torch::nn::Linear>()->forward(
torch::concat({e, nonCondView.unsqueeze(-1)}, -1)
)
);
auto p2 = flow2Param[i]->as<torch::nn::Linear>()->forward(localEmbed);
auto scale2 = torch::softplus(p2.index({torch::indexing::Slice(), 1}));
auto shift2 = p2.index({torch::indexing::Slice(), 0});
auto condView = data.index({torch::indexing::Slice(), conditionalDim});
condView.div_(scale2);
condView.sub_(shift2);
jacobianSum -= torch::log(scale2);
conditionalDim ^= 1; // Flip Conditionality
}
torch::apply([](auto& datum){ datum = -0.5 * (datum*datum); }, data);
data = torch::sum(data, -1);
if(torch::any(torch::isnan(data)).item<bool>()){
std::cout << augmentedData.index({torch::nonzero(torch::isnan(data)).squeeze()}).slice(-1, -4) << std::endl;
std::cout << "Detected NaNs! Dumping all values ^" << std::endl;
std::exit(1);
}
return -1.0 * (data + jacobianSum); // Apply the Jacobian and return NLL
}
// @todo Add sampling function
void train(int epochs, torch::Tensor data, double threshold = 1e-6){
torch::optim::Adam optim(
this->parameters(),
torch::optim::AdamOptions(1e-3).betas(std::make_tuple(0.5, 0.5))
);
int patience = 0;
double lastBestLoss = INFINITY;
for(int epoch = 1; epoch <= epochs; epoch++){
this->zero_grad();
auto loss = this->forward(data).mean(); // Mean NLL Loss
double lossScalar = loss.item<double>();
loss.backward();
torch::nn::utils::clip_grad_norm_(this->parameters(), 1.0); // Clip Gradients For Stability
optim.step();
if(lossScalar + threshold < lastBestLoss){
patience = 0;
lastBestLoss = lossScalar;
}
else{
patience++;
}
if(patience > 50){
std::cout << "Early Stopping at " << epoch << std::endl;
break;
}
if(epoch % 10 == 0)
std::cout << "Average Loss of {" << lossScalar << "} at Epoch " << epoch << std::endl;
}
}
private:
int numFlows;
// Embedding Block (Generate an internal representation from the context)
torch::nn::Linear l1e;
// Flow Blocks
torch::nn::ModuleList flow1Lin;
torch::nn::ModuleList flow2Lin;
torch::nn::ModuleList flow1Param;
torch::nn::ModuleList flow2Param;
};
/**
* @brief Generate data under the stochastic Lotka-Voltera model.
*/
torch::Tensor generativeModel(boost::random::mt19937& rng, double time, int numSamples, torch::Tensor initState, double birthRate, double predationRate, double deathRate){
// Put a floor on these values
birthRate += 1e-2;
predationRate += 1e-2;
deathRate += 1e-2;
torch::Tensor currentState = initState;
double currentTime = 0.0;
double sampleFrequency = time / (double)(numSamples);
int currentSample = 1;
torch::Tensor samples = torch::zeros({numSamples, 2});
samples.index_put_({0}, initState);
// Simulate with the Gillespie algorithm
while(currentSample < numSamples){
double currentPrey = currentState[0].item<double>();
double currentPredators = currentState[1].item<double>();
if(currentPrey == 0.0 && currentPredators == 0.0){ // Quit upon total extinction
break;
}
double birthPoisson = birthRate * currentPrey;
double predationPoisson = predationRate * currentPredators * currentPrey;
double deathPoisson = deathRate * currentPredators;
double exponentialRaceRate = birthPoisson + predationPoisson + deathPoisson;
double waitingTime = boost::random::exponential_distribution<double>{exponentialRaceRate}(rng);
currentTime += waitingTime;
double randomUpdate = boost::random::uniform_01<double>{}(rng);
if(randomUpdate < birthPoisson / exponentialRaceRate){
currentPrey++;
}
else if(randomUpdate < (birthPoisson + predationPoisson) / exponentialRaceRate){
currentPrey--;
currentPredators++;
}
else{
currentPredators--;
}
currentState.index_put_({0}, currentPrey);
currentState.index_put_({1}, currentPredators);
// Catch up on (potentiall multiple) sampling events
for(; currentTime >= sampleFrequency * (double)currentSample && currentSample < numSamples; currentSample++){
samples.index_put_({currentSample}, currentState);
}
}
auto shiftedSamples = torch::roll(samples, 1, 0);
auto multiplicativeIncrease = torch::divide(samples, shiftedSamples);
multiplicativeIncrease = torch::where(torch::isnan(multiplicativeIncrease), 1e-6, multiplicativeIncrease);
multiplicativeIncrease = torch::where(multiplicativeIncrease == 0.0, 1e-6, multiplicativeIncrease);
shiftedSamples = torch::where(shiftedSamples == 0.0, 1e-6, shiftedSamples);
auto augmentedData = torch::concat({shiftedSamples, multiplicativeIncrease}, -1);
augmentedData = augmentedData.slice(0, 1, augmentedData.size(0));
return augmentedData;
}
int main(int argc, char** argv){
auto rng = boost::random::mt19937{1124};
double initPrey = 60.0;
double initPredator = 10.0;
double truePreyBirth = 0.75;
double truePredation = 0.01;
double truePredatorDeath = 0.9;
double simulationTime = 40;
int numSamples = 200;
auto initState = torch::tensor({60.0, 10.0});
std::cout << "Simulating Data..." << std::endl;
auto simulatedData = generativeModel(rng, simulationTime, numSamples, initState.clone(), truePreyBirth, truePredation, truePredatorDeath);
std::cout << simulatedData << std::endl;
auto trainingData = torch::empty({0, 7});;
int numSNLEIterations = 4;
int mcmcIterations = 20000;
int samplingFrequency = 1000;
int priorSamples = 100;
int samplingIterations = 10;
std::array<double, 3> lambdas = {3.0, 20.0, 3.0};
auto unif = boost::random::uniform_01();
for(int i = 1; i <= numSNLEIterations; i++){
std::cout << "Starting SNLE Iteration " << i << std::endl;
if(i > 1){
ConditionalAutoregressiveFlow neuralLikelihood(4);
neuralLikelihood.train(5000, trainingData);
std::array<double, 3> currentParams = {
boost::random::exponential_distribution{lambdas[0]}(rng),
boost::random::exponential_distribution{lambdas[1]}(rng),
boost::random::exponential_distribution{lambdas[2]}(rng)
};
double currentPrior = 0.0;
for(int i = 0; i < 3; i++){
currentPrior += std::log(lambdas[i]) - lambdas[i] * currentParams[i];
}
auto simDim = simulatedData.size(0);
double currentLL = -1.0 * neuralLikelihood.forward(
torch::concat({
torch::full({simDim, 1}, currentParams[0]),
torch::full({simDim, 1}, currentParams[1]),
torch::full({simDim, 1}, currentParams[2]),
simulatedData
}, 1)
).sum().item<double>();
for(int j = 1; j <= mcmcIterations; j++){
for(int gibbsIter = 0; gibbsIter < 3; gibbsIter++){
double scalingFactor = std::exp(1.5 * (unif(rng) - 0.5));
std::array<double, 3> newParams = currentParams;
newParams[gibbsIter] = currentParams[gibbsIter] * scalingFactor;
double newPrior = 0.0;
for(int i = 0; i < 3; i++){
newPrior += std::log(lambdas[i]) - lambdas[i] * newParams[i];
}
double newLL = -1.0 * neuralLikelihood.forward(
torch::concat({
torch::full({simDim, 1}, newParams[0]),
torch::full({simDim, 1}, newParams[1]),
torch::full({simDim, 1}, newParams[2]),
simulatedData
}, 1)
).sum().item<double>();
double logRatio = std::log(scalingFactor) + newLL - currentLL + newPrior - currentPrior;
if(std::log(unif(rng)) <= logRatio){
currentPrior = newPrior;
currentLL = newLL;
currentParams = newParams;
}
}
if(j % samplingFrequency == 0){
for(int simIter = 0; simIter < samplingIterations; simIter++){
auto newData = generativeModel(rng, simulationTime/4.0, numSamples/4, initState.clone(), currentParams[0], currentParams[1], currentParams[2]);
auto newDataDim = newData.size(0);
newData = torch::concat({
torch::full({newDataDim, 1}, currentParams[0]),
torch::full({newDataDim, 1}, currentParams[1]),
torch::full({newDataDim, 1}, currentParams[2]),
newData
}, 1);
trainingData = torch::concat({trainingData, newData}, 0);
}
std::cout << j << " ( " << currentLL << " ):\tBirth: " << currentParams[0] << "\t Predation: " << currentParams[1] << "\tDeath: " << currentParams[2] << std::endl;
}
}
}
else {
for(int j = 1; j <= priorSamples; j++){
std::array<double, 3> currentParams = {
boost::random::exponential_distribution{lambdas[0]}(rng),
boost::random::exponential_distribution{lambdas[1]}(rng),
boost::random::exponential_distribution{lambdas[2]}(rng)
};
for(int simIter = 0; simIter < samplingIterations; simIter++){
auto newData = generativeModel(rng, simulationTime/4.0, numSamples/4, initState.clone(), currentParams[0], currentParams[1], currentParams[2]);
auto newDataDim = newData.size(0);
newData = torch::concat({
torch::full({newDataDim, 1}, currentParams[0]),
torch::full({newDataDim, 1}, currentParams[1]),
torch::full({newDataDim, 1}, currentParams[2]),
newData
}, 1);
trainingData = torch::concat({trainingData, newData}, 0);
}
std::cout << j << "\tBirth: " << currentParams[0] << "\t Predation: " << currentParams[1] << "\tDeath: " << currentParams[2] << std::endl;
}
}
}
// Run MCMC one final time to get a trace file
ConditionalAutoregressiveFlow neuralLikelihood(4);
neuralLikelihood.train(5000, trainingData);
int mcmcSamplingFreq = 100;
int finalMcmcIter = 50000;
std::ofstream outputFile("./output.trace");
outputFile << "Iteration\tPosterior\tBirthRate\tPredationRate\tDeathRate" << std::endl;
std::array<double, 3> currentParams = {
boost::random::exponential_distribution{lambdas[0]}(rng),
boost::random::exponential_distribution{lambdas[1]}(rng),
boost::random::exponential_distribution{lambdas[2]}(rng)
};
double currentPrior = 0.0;
for(int i = 0; i < 3; i++){
currentPrior += std::log(lambdas[i]) - lambdas[i] * currentParams[i];
}
auto simDim = simulatedData.size(0);
double currentLL = -1.0 * neuralLikelihood.forward(
torch::concat({
torch::full({simDim, 1}, currentParams[0]),
torch::full({simDim, 1}, currentParams[1]),
torch::full({simDim, 1}, currentParams[2]),
simulatedData
}, 1)
).sum().item<double>();
for(int j = 1; j <= finalMcmcIter; j++){
for(int gibbsIter = 0; gibbsIter < 3; gibbsIter++){
double scalingFactor = std::exp(1.5 * (unif(rng) - 0.5));
std::array<double, 3> newParams = currentParams;
newParams[gibbsIter] = currentParams[gibbsIter] * scalingFactor;
double newPrior = 0.0;
for(int i = 0; i < 3; i++){
newPrior += std::log(lambdas[i]) - lambdas[i] * newParams[i];
}
double newLL = -1.0 * neuralLikelihood.forward(
torch::concat({
torch::full({simDim, 1}, newParams[0]),
torch::full({simDim, 1}, newParams[1]),
torch::full({simDim, 1}, newParams[2]),
simulatedData
}, 1)
).sum().item<double>();
double logRatio = std::log(scalingFactor) + newLL - currentLL + newPrior - currentPrior;
if(std::log(unif(rng)) <= logRatio){
currentPrior = newPrior;
currentLL = newLL;
currentParams = newParams;
}
}
if(j % mcmcSamplingFreq == 0){
outputFile << j << "\t" << currentLL + currentPrior << "\t" << currentParams[0] << "\t" << currentParams[1] << "\t" << currentParams[2] << std::endl;
std::cout << j << " ( " << currentLL << " ):\tBirth: " << currentParams[0] << "\t Predation: " << currentParams[1] << "\tDeath: " << currentParams[2] << std::endl;
}
}
return 0;
}